Interoperable Speed Data Using SharedStreets
By Mollie Pelon McArdle in Pilot Perspective · May 13, 2019
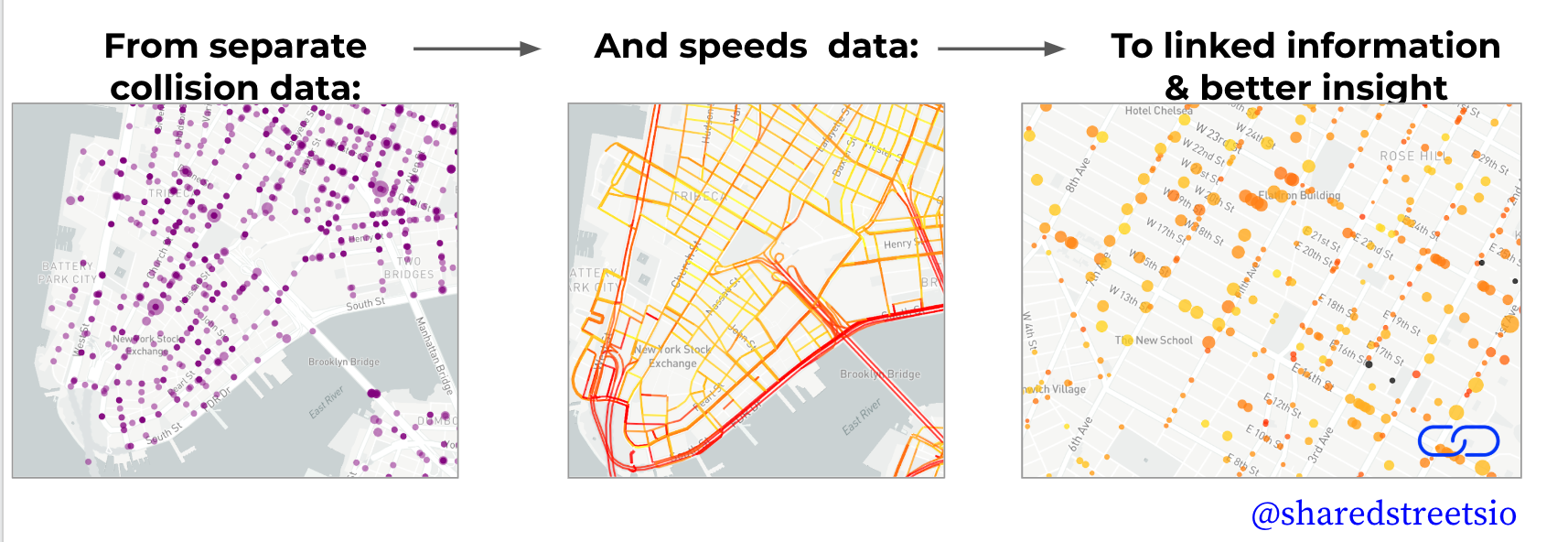
Data on vehicle speeds are critical for designing safer streets – but it’s only one tool in a city’s digital arsenal. With Uber’s release of their new speed datasets linked to the SharedStreets referencing system, these important new datasets can be translated and linked with existing city data and tools, to create a fuller picture of what’s happening on city streets. SharedStreets is designed to unlock the old walled gardens, so cities and companies can work together to design streets that work better for everyone.
SharedStreets references are unique identifiers that allow data linked to different basemaps to be linked together. To learn more about how the SharedStreets referencing system works, see the documentation here.
In this post, we will walk through an example of how SharedStreets can link incompatible datasets by combining Uber’s speed data with bicycle and pedestrian injury collisions in New York City. This is just one example of how this speed data can be combined with any street-linked dataset using SharedStreets.
To learn more about how the SharedStreets referencing system works, see the post here.
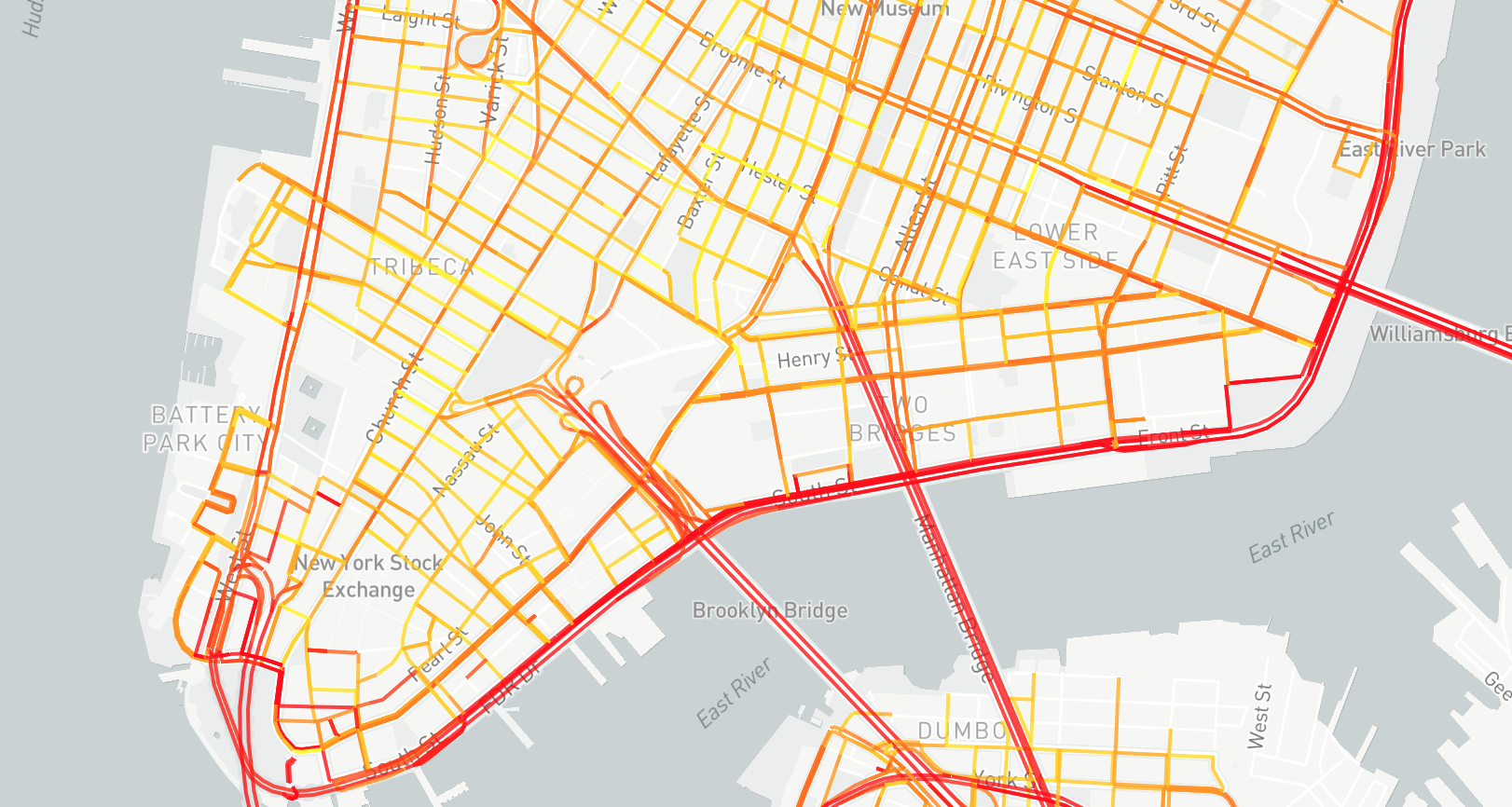
Step 1: Linking Uber Speed Data with SharedStreets
Uber’s speed data sets are generated using an OpenStreetMap (OSM) derived road network. Uber makes data available using their own internally defined “segment” and “junction” identifiers, and provides a set of index files that relate their internal IDs back to the original OSM way and node IDs. In order to visualize this data it needs to be linked with a map. Building on our general purpose data processing library and command line interface (CLI) SharedStreets developed tools for extracting Uber speed data and connecting Uber segments and junctions with SharedStreets References and an OSM-derived geometries.
To get started download the Uber speed data for a given city from the Uber Movement portal. The data set consists of several zipped files in CSV format. You will need the segment and junction data files, as well as either the quarterly “hour of day” aggregate summary, or “hourly” speed data for a given month. Once downloaded extract the zipped files into a directory.
Next install the SharedStreets speed tool using yarn or npm:
$ yarn global add sharedstreets-speeds
$ npm install -g sharedstreets-speeds
To extract the data from Uber files create a geojson polygon enclosing the area of interest. You can use a GIS program or a free online tool such as GeoJSON.io to draw the polygon. This file will act as a filter – only road segments with speed data inside the polygon will be exported.
Finally, run the SharedStreets tool to extract data and link with the SharedStreets referencing system:
$ shst-speeds movement filter_area_polygon.geojson
--movement-segments=movement-segments-to-osm-ways-new-york-2018.csv
--movement-junctions=movement-junctions-to-osm-nodes-new-york-2018.csv
--movement-quarterly-speeds=movement-speeds-quarterly-by-hod-new-york-2018-Q4.csv
Using the default settings the tool will produce a GeoJSON file containing a record for each directional street segment for each hour in the data set. In addition to the geometry and speed data, each segment contains the SharedStreets Reference ID in record the properities, which will be used in the next step to combine with NYC crash data.
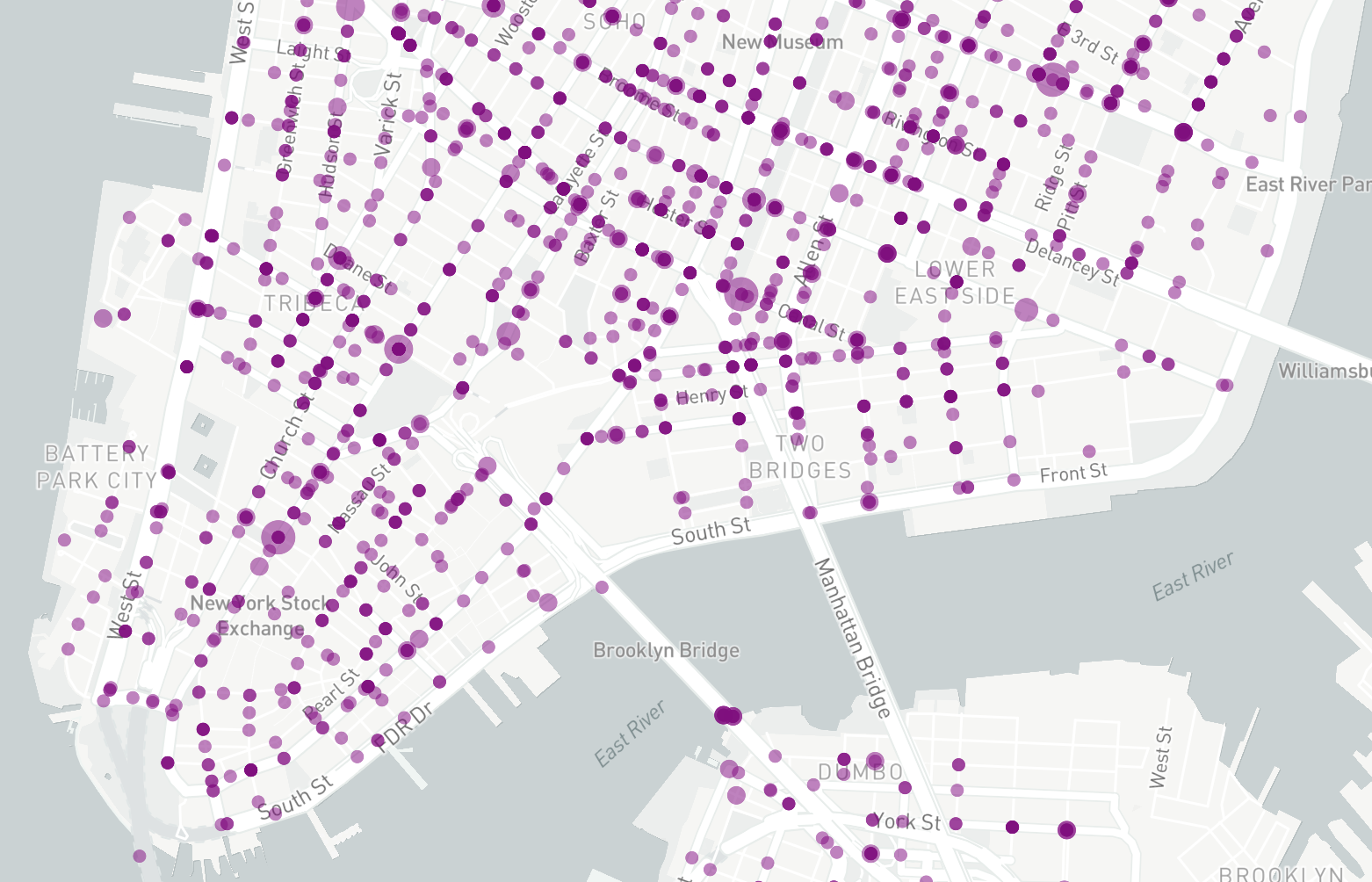
Step 2: Clustering Crash Data using SharedStreets
In this step we’ll use the general SharedStreets data processing tools to cluster crash data and link with SharedStreets references. For this example we’re using the NYPD Motor Vehicle Collisions data set available here in CSV format. Before processing, this data will need to be converted from CSV to GeoJSON format using your preferred GIS tool. This data set is very large so we also recommend selecting subset of the data matching the area used for extracting the speed data.
Once the crash data is prepared install the general purpose SharedStreets CLI using yarn or npm:
$ yarn global add sharedstreets
$ npm install -g sharedstreets
Next use the SharedStreet CLI to cluster the point data along the street:
$ shst match nypd_crash_data.geojson
--cluster-points=10
The settings above will process each crash data point, snapping it to the nearest SharedStreets reference, and aggregate with other data points for each 10 meter interval along the street. The total count of points and the sum of all numeric properties will be stored in the clustered data set and included in the output GeoJSON file. The SharedStreets reference IDs for each cluster will be stored in the GeoJSON properties and can be joined with the references in the speed data set from the previous step.
Step 3: Combining Speed and Crash Data
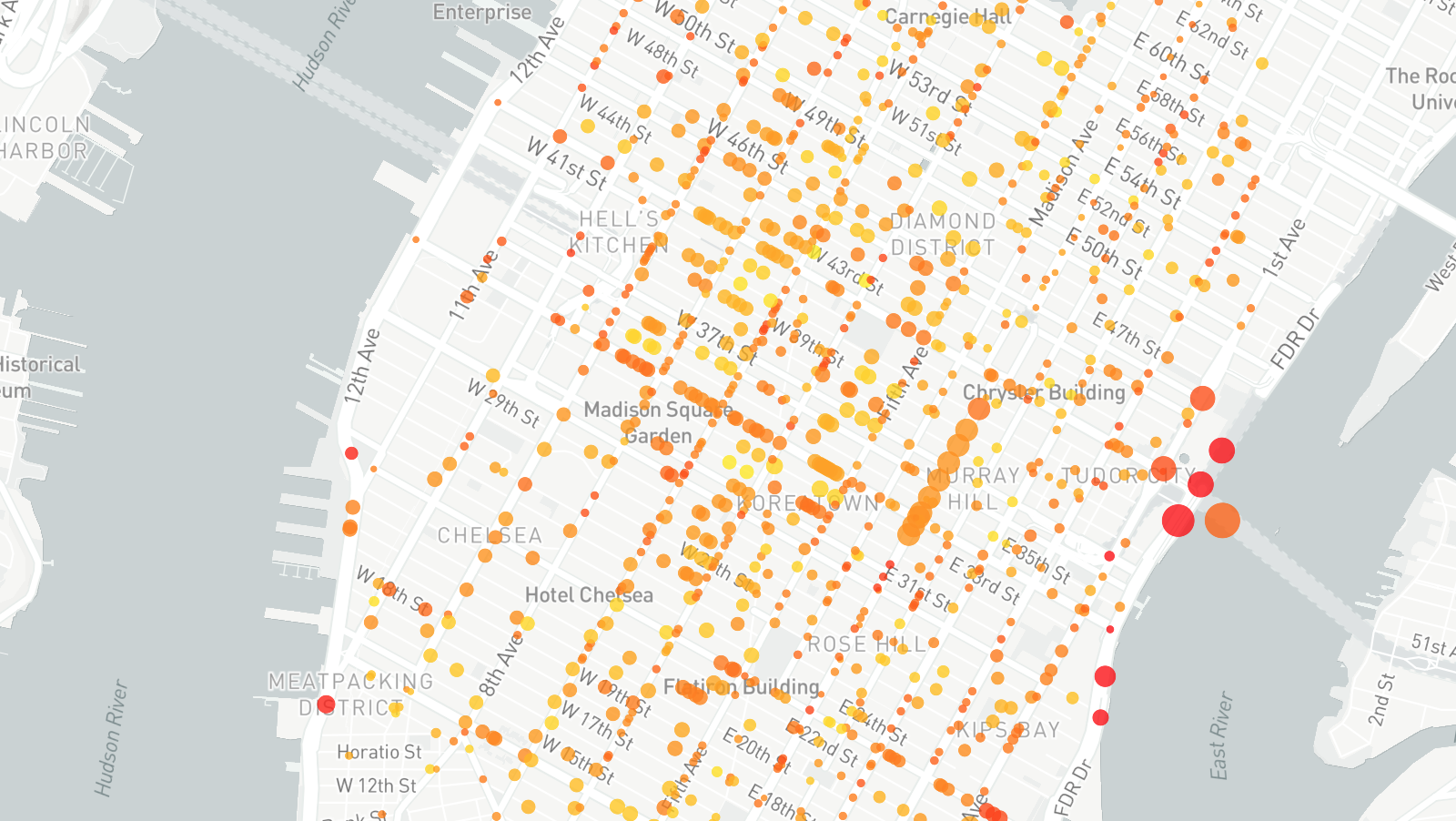
Finally, open both the speed and crash output files in a GIS program. Join the two data sets using the SharedStreets Reference ID column in each file. Once joined the speed and crash statistics data will be linked and can be used to visualize relationship between speed and injuries. The map below colors crash clusters using related roadway speeds, and the size of each cluster reflects the number of injured persons.
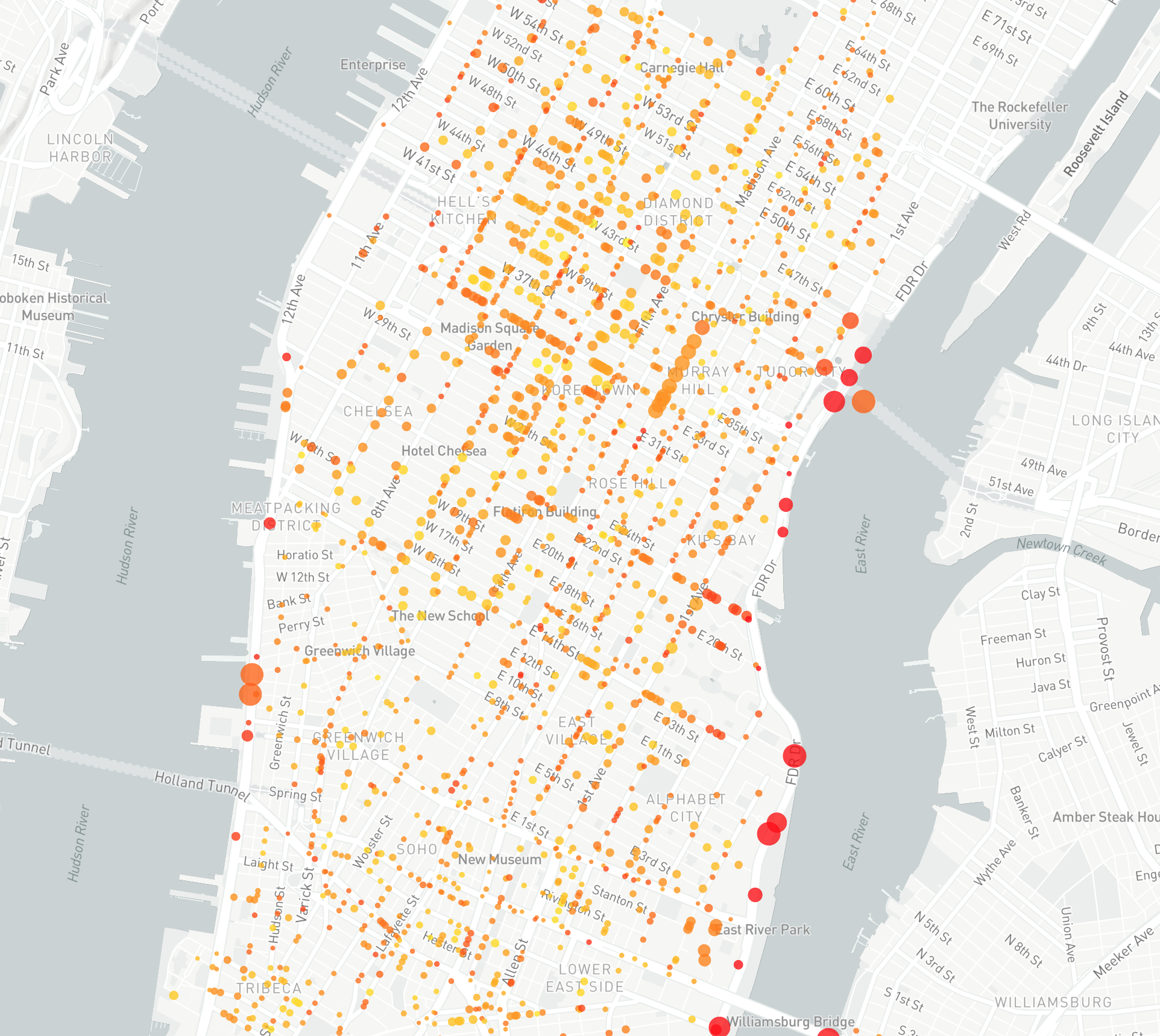
This example shows how city Uber’s speed dataset can be linked to a collision dataset. This is traditionally a challenging problem to overcome as both datasets come from different sources. Third-party datasets (and even a city’s own GIS datasets) often require manual reconciliation to combine because base maps do not match. This makes it difficult and cumbersome to port information between different maps. However, the SharedStreets referencing system creates a common way to refer to streets, making it much easier to perform analysis and answer questions about what’s happening in a city — from speeds and collisions to micromobility.
For more examples of how SharedStreets can support a city’s workflows, see our other blog posts. If you have questions or run into difficulties, reach out–we’re here to help!


Get Involved
Do you work for a city or government agency? A private company? Or are you an independent researcher or developer? Learn how to start using the SharedStreets Toolkit.
Get Started